Abstract
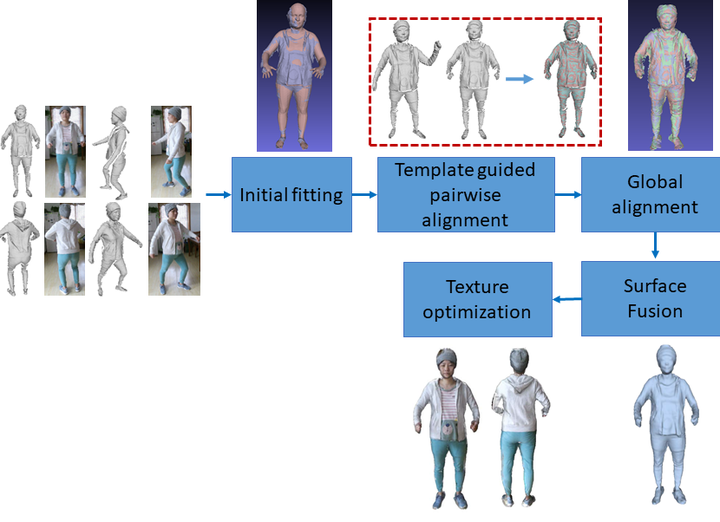
In this paper, we propose a novel approach to reconstruct 3D human body shapes based on a sparse set of RGBD frames using a single RGBD camera. We specifically focus on the realistic settings where human subjects move freely during the capture. The main challenge is how to robustly fuse these sparse frames into a canonical 3D model, under pose changes and surface occlusions. This is addressed by our new framework consisting of the following steps. First, based on a generative human template, for every two frames having sufficient overlap, an initial pairwise alignment is performed; It is followed by a global non-rigid registration procedure, in which partial results from RGBD frames are collected into a unified 3D shape, under the guidance of correspondences from the pairwise alignment; Finally, the texture map of the reconstructed human model is optimized to deliver a clear and spatially consistent texture. Empirical evaluations on synthetic and real datasets demonstrate both quantitatively and qualitatively the superior performance of our framework in reconstructing complete 3D human models with high fidelity. It is worth noting that our framework is flexible, with potential applications going beyond shape reconstruction. As an example, we showcase its use in reshaping and reposing to a new avatar.